|
日時:
2012年5月15日(火) 13:00~15:30 演題:
世界一のスーパーコンピュータ「京」の開発物語 講師: 富士通株式会社 フェロー 井上 愛一郎
氏
元々工場の製造ラインなどの機械屋で、コンピュータは全くの素人であったが、この分野に飛び込んで大暴れしてみて、CPUの開発を担い、スーパーコンピュータの開発を担うことになった。富士通に入社以来、CPUの開発をライフワークとして、一生懸命やってきた。その集大成がスーパーコンピュータ「京(けい)」である。富士通のコンピュータ開発は、結果として「京」の世界一まで順調に来たかのようであるが、道のりは決して平坦ではなかったとつくづく感じている。
1.コンピュータことはじめ
富士通の沼津工場は第一東名と第二東名の中間にあり、池田記念ホールにはリレー制御のFACOM128Bが展示されており、女性が実際に動かして説明してくれる。このコンピュータは1959年製で、最初のコンピュータFACOM100から数えて三つ目かそこらのものであるが、未だ現役として動く。延命プロジェクトとして、還暦(60年)まで動かそうとしている。池田敏雄氏が富士通でコンピュータを始めた当時(FACOM10周年)の新聞には、「レンズ設計に活躍」、「YS-11の設計に」、「データーセンター開設」などの記事が掲載されている。コンピュータの真髄は、人間が到底できない計算能力である。コンピュータは計算能力を究極まで高めることで評価されるべきで、50年を経てFACOMが復活したという想いである。
2.コンピュータ開発の歴史
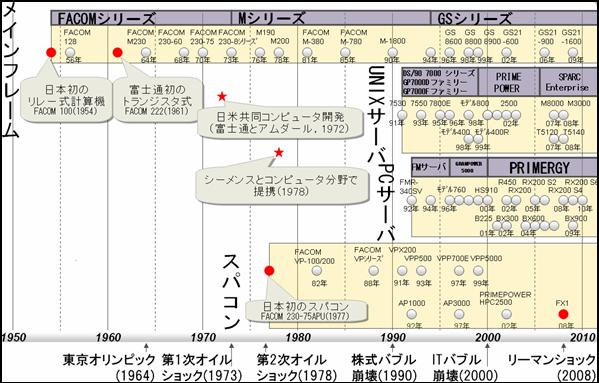
富士通におけるコンピュータ開発の歴史を下図に示す。
日本初のリレー式計算機FACOM100(1954年)から始まり、最初はFACOMシリーズ、途中からM(モデル)シリーズになり、FACOM230-60や230-75から、異論はあると思うが日本初のスパコンとも言えるFACOM230-75APU(1977年)へと進化させた。最初は独自の仕様で独自の進化を遂げたが、世界で勝負するためにはソフトウェアの互換性が非常に重要であることから、日立製作所と機種ごとに分担して互換機を開発し、Mシリーズに切り替わった。しかし、技術的には黎明期からの独自技術で独自開発の歴史を踏んだ上での登場である。
Mシリーズの基本的な素子は、メインフレーム(大型汎用コンピュータ)用としてスイチング速度が速ければ消費電力を気にしないものであった。IBM互換のMシリーズであったが、常にIBMより進化した素子を使い、IBMより高い性能を狙うものであった。世間では富士通は「京」で世界一になったとか、少し前のUNIXサーバのスコアで世界一を獲ったとか、それで富士通はついにIBMを抜いたとか言われるが、FACOMシリーズやMシリーズでも既にIBMに引けをとるものではなく、先進的な取組みによって技術的にはリードしていたと考えている。
Mシリーズは約20年続き、GSシリーズになった。1990年代初めに登場したUNIXサーバやPCサーバで使用されている素子は、CMOS素子である。Mシリーズの素子はトランジスタ、IC、LSI、超LSIと進化したが、チップ間伝送と熱の問題で性能的な優位性を保てなくなり、高密度・低消費電力のCMOS素子を採用したのがGSシリーズである。
正式にスパコンと呼んでいるのはFACOM VP100/200(1982年)からで、M‐380をホストとし、演算能力を補ったものである。ベクトル演算方式のVPシリーズは、並列化したVPPシリーズに替わり、VPP2000(1999年)まで続いた。背後にスカラを並列化したAP1000(1992年)、AP3000(1997年)があった。2000年を境にして、富士通は本格的なスパコン専用機から撤退したが、ビジネス機と共通化したHPC2500(2002年)で繋いだ。今回の「京」も例に漏れないが、スパコンのビジネスは厳しい。それでもVPPの時代には欧州にも納入していたので、「京」の開発に際して欧州を廻った際には、ユーザーから「富士通が戻ってきたのか。非常に期待している」と言われた。
約50年の歴史の中で進化と停滞が繰り返した。FACOM128B(1958年)ではリレー数千個を用いて複数のラックで一つのCPUを構成していたが、約30年後のM-780(1985年)では約300個のLSI(ECL)で1枚のCPUボードができるようになった。コンピュータの性能を上げると熱が問題となった。M-780はボードの両面から水冷しており、約10年後のM-1900(1994年)も同様に水冷で、約100個のLSI(ECL)で1枚のCPUボードができるようになったが、10年も掛かって1/3にしかならなかった。より集積度の高いLSIを用いても冷却上の制約から1チップに載せられる回路量が制約され、やはり約100個のLSIが必要となった。そうするとチップ間の伝送も問題となった。このため、消費電力が小さく1チップに沢山の回路が搭載できるCMOSに替わっていくことになった。M-1900から僅か2年後のGS8600(1996年)では、8個(演算用5個とキャッシュ用3個)のCMOSで1つのCPUが構成された。その後にCMOSが進歩し、GS21-1600(2009年)では1個のチップが1個のCPUとなっている。M-1900(1994年)のLSIからGS8600(1996年)のCMOSになり、設置面積は28%、重量は24%、消費電力と発熱量は12%になった。
しかし、黎明期から最新のGSシリーズやUNIX機に至るまで、筐体については1台のコンピュータが1台の筐体に収納され、筐体を外から見ると50年間何も変わっていないように見える。前のマシンで動かしていたソフトを新しいマシンで動かすと、より速く動く。次のマシンで動かしたら、さらに速く動く。と言うように、ソフトは変えずにマシンの性能だけを上げて、処理能力を高めてきたからである。
富士通のCMOSプロセッサの開発は、新しい種々の高性能技術を取り入れてきたが、それと同時に高信頼技術を継承してきた。富士通のマシンは簡単には壊れない。沼津工場には池田記念ホールとは別にDNA館があり、最近まで動いていた富士通の古いマシンを展示している。高信頼性に拘って堅牢な造りをしているので、製品保証は10年(最近は5年)だが、30年も40年も現役で動いていたマシンもある。
最近のCMOSの進化の例を見ると、GS21-600は130nm世代、GS21-900は90
nm世代、GS21-1600は65 nm世代と微細化が進んだ。これに対応してUNIXサーバでは、130nm世代がSPARC64 V、90 nm世代がSPARC
64VとSPARC 64Ⅵ、65 nm世代がSPARC 64Ⅶに使用された。そしてCMOSの進化に伴い、1チップに載っているCPUの数が1個、2個、4個と増えた。筐体からは分からないがチップはどんどん進化した。
この進化を外から見て分かる大きな変化としたのが「京」である。すなわちSPARC Enterprise(2007年)までは1台の筐体が1台のコンピュータであったが、「京」(2011年)では1台の筐体に128個のコンピュータを収納するようにした、これは概念を変えたと言える。改めて、この「京」のCPUをCMOSの最初の大型コンピュータGS8600と比べると、GS8600の1枚のシステムボードが15年後に1個のチップになったと見ることができる。
3.スーパーコンピュータとは
スーパーコンピュータとは、卓越した計算能力を有し、その時代の一般のコンピュータよりも極めて高速な計算機である。黎明期のFACOM128Bなども、当時としては卓越した計算能力という意味ではスーパーコンピュータと言っても過言ではない。しかし現在の政府調達における定義では、演算速度1.5TFlops(テラ・フロップス)以上となっている。T(テラ)は1兆、Flops(Floating point number Operations
Per Second :フロップス)は1秒間に計算できる浮動小数点演算回数であるので、1.5TFlops(テラ・フロップス)は1.5兆回の浮動小数点演算回数に相当する。因みにスーパーコンピュータ「京」は10PFlops(ペタ・フロップス)の計算能力を有しており、P(ペタ)はT(テラ)の千倍、京(ケイ)は兆の1万倍であるので、1秒間に10ペタ回=1京回の浮動小数点演算が可能である。したがって政府調達における定義は時代とともに変わるべきものである。「京」コンピュータの京は、単位を表すだけでなく、門すなわち門出も意味している。
スーパーコンピュータの卓越した計算能力は、大規模・高解像度可視化シミュレーション(計算機上の模擬実験)に使われる。膨大な時間が掛かる実験、宇宙での実験、津波などの災害の実験、原子レベルのようなミクロな話などはできないので、シミュレーションによって時間の制約、空間の制約、費用の制約を超越することができる。科学の進歩にとっては欠かせない重要な道具である。
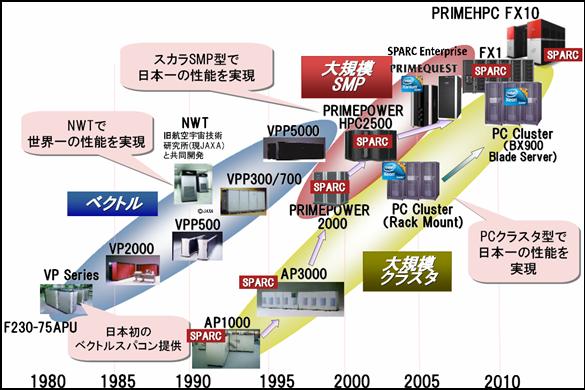
4.スーパーコンピュータ開発の歴史 富士通のスーパーコンピュータの開発の歴史を下図に示す。
FACOM230-75APUに始まり、ベクトル型のVPシリーズから本格的なスーパーコンピュータである。VPシリーズは以降VP2000、並列したVPP500、VPP300/700、VPP5000があるが、旧航空宇宙技術研究所(現、JAXA)と共同開発したNWT(数値風洞トンネル)で、世界一の性能を達成した。一方、並列に沢山並べて性能を上げる大規模クラスタ型は1990年頃に富士通研究所で始まり、AP1000、AP3000が作られたが、専用機として作ることを止めて、その技術はVPP5000の技術とともに大規模SMP型のPRIMEPOWER
HPC2500(JAXAに納入し、スカラSMP型で日本一の性能を実現)に引き継がれた。次にJAXAに納入されたFX1では、「京」に先立って一つの筐体に沢山のコンピュータを入れて並列に動かすと言う概念が導入された。ただし、使われたCPUは商用機に使われていたものを使用し、若干のスパコン機能は入れたものの、最初からスパコンをターゲットにしていなかったことから、チップ数が多くなり、実装密度は余り上げられなかった。そして「京」が登場し、その「京」の技術を用いて更に筐体当たりの性能を高めた商用機としてPRIMEHPC
FX10を開発した。
5.TOP500および世界一位獲得
世界で最も速いスパコン上位500システムをランキングするプロジェクトが1993年に発足した。LINPACKベンチマーク(連立一次方程式を解く速度を測定し、システムの浮動少数点演算性能を評価)の結果に基づいて、年2回結果が公表される。2010年6月までの性能ベースの国別シェアを見ると大半が米国で、日本はかつて2位であった。NWTの時代と地球シミュレータのころにシェアが高くなっているが、その後は急速に低下した。一方、中国は近年世界一のスパコンを出し、台頭してきている。日本のスパコンが衰退し、富士通もビジネスから及び腰だったが、「京」は昨年6月に8.162
PFlops(2位の3倍)と圧倒的な世界一になり、11月には10.51 PFlops(2位の4倍)を達成し、連覇した。
人が二桁の掛算を5秒でできるとすれば、1京(10P)回の計算実行には16億年掛かる。また、東京ドームの観客5万人が電卓を使用して、1秒間に1回の計算をするとすれば、6,400年掛かる。5万人の内には、10人や100人は計算間違いもするであろう。これを一切間違えずに僅か1秒で行うことを考えていただければ、「京」の能力の高さが理解いただけるでしょうか?
2011年11月公表のTOP500リストのTOP10は下記の通りである。
この表で、ほとんどのシステムには米国の汎用技術が使われている。独自技術で上位にランクインできるスーパーコンピュータが作れる国は米国と日本に限られていると言える。日本は、1993年JAXAのNWT、1996年筑波大学計算物理学研究センタのCP-PACS(演算に特化した専用機)、2002から2004年海洋研究開発機構の地球シミュレータ、2011年理化学研究所の「京」が世界1位を獲得している。これらの日本のスーパーコンピュータは、いずれも日本の独自技術によるものであり、そこが中国とは異なる。地球シミュレータが世界一で連覇した時、米国は宇宙開発でのスプートニク・ショックのようなショックを受け、その後必死になって追い上げ、独壇場を築いたが、そんな中で「京」が世界一を獲得した。
スーパーコンピュータは実際に使って評価されるべきものなので、LINPACKベンチマークの他に実際のアプリケーションの分野での評価がある。ゴードン・ベル賞はハードウェアとアプリケーションの両方で優れた成果を挙げた論文に付与される賞で、「京」は実行性能部門で最高性能賞を獲得した。また、スパコンの総合的な性能を評価するHPCチャレンジ賞では4部門すべてで第1位を獲得した。これらの受賞は、高い演算性能と多様なアプリケーションに対応できることを目指して開発した成果と考える。
6.スーパーコンピュータ「京」とその技術
(1)開発の歴史
「京」の開発は、2005年に文部科学省のプロジェクト「最先端・高性能汎用スーパーコンピュータの開発利用」に始まった。富士通は当時スーパーコンピュータをほとんどやっておらず、他のベンダーも失敗の確率が高く、お金も持ち出しになる可能性が高いことから、いずれも本音では迷惑がっていた。とは言うものの、富士通、日本電気、日立製作所の日本を代表する三社が共同して製作すべく概念設計を開始し、2007年に終了した。
その後本格的な設計に入ったが、2009年にはいろいろなことが起きた。日本電気と日立製作所が5月に撤退して富士通のみが取り残された。11月には事業仕分けで蓮舫さんが出てきて「2位じゃ駄目なんでしょうか」と言い、「予算上見送りに近い縮減(事実上の凍結)」と判定された。富士通は既に本格的に開発を進めており、5月にはSPARC64Ⅷfxを発表し、9月には「京」の試作第一号機を動かし始めていた。
2010年に理化学研究所の組織「計算科学研究機構」ができ、「京」の第一号筐体が納入され、記念式典が開催された。2011年にLINPACKベンチマークで世界一位を達成した。期を同じくして、「京」をベースにしたPRIMEHPC
FX10の販売を開始し、東京大学などに納入した。
(2)スーパーコンピュータ実現に向けたハードル
大量データ(ビッグデータ)の大量処理に対応したコンピュータが求められている。3台のマシンを比較すると、下表のようになる。
(注)最近はCPUチップ1個に複数のCPU機能があり、CPU機能の数をコア数と呼ぶ。
10PFlopsといった高性能スパコンでは膨大な数のコンピュータを同時に動かす必要があるため、実用に向けては、①省スペース、②低消費電力、③高信頼性が大きな課題である。
「京」は33m四方のスペースに、102個のCPUを搭載した筐体が864個設置されている。LINPACK性能とLINPACK実行効率の関係において、「京」は圧倒的な高性能でかつ高効率(およそ93%)を有する。LINPACK性能と電力性能の関係において、LINPACK性能の低いマシンでは高い電力性能を有するものもあるが、「京」のように圧倒的に高い性能のマシンとしては、良好な電力特性を示している。今後は「京」で行ったコンピュータの作り方の概念を更に進化させることにより、より高い電力特性にすることができると考えている。
「京」に搭載されたプロセッサはSPARC64TMⅧfxで、富士通のメインフレームをベースにした独自開発のSPARC互換CPUである。(サン・マイクロシステムズのSPARCに互換性のあるプロセッサで、サン・マイクロシステムズの技術によるものではない。)システム機能の集約、低消費電力、高信頼性を念頭に置いて設計された。CPUは宇宙線の衝突によりデータが変化し、間違った計算結果を出力する可能性があるが、SPARC64TMⅧfxはハードによるエラーを検出して自己修復する機能を有するが、他社のCPUよりも広範囲でのエラー対応力を実現した。エラー検出・自己修復機能が世界で一番優れていると言って過言ではない。
超超並列システムはTofuと呼ぶインターコネクトによってノード(1つのコンピュータの単位)同志が接続される。ソフトウェアとハードウェアの協調によって、コア間およびノード間の並列処理を可能にしている。Tofuは冗長なパスを持っていて、故障したノードを回避できるようになっている。
1枚のシステムボードに4個のノードを載せて、水冷することにより低消費電力と高信頼性を実現している。今後は100個とか1,000個を載せるか、ボードの大きさを1/10とか1/100にしたい。1台のラックには約100個のノードが搭載されているが、ここにも工夫がある。水冷と空冷によるハイブリッド冷却を採用し、冷却性と高密度を両立させるため、斜めに実装している。
(3)エピソード
計画・立案時には、やめたはずのスパコンの超大規模開発であり、社内のほとんどの人は反対し、事業部側は誰も引き受けなかった。それで、富士通研究所のプロジェクトとして国家プロジェクトに参加し、その後社長プロジェクトとなって本格的に開発が始まった。2009年は日本電気と日立製作所がプロジェクトから離脱したり、事業仕分けなど大変な年であったが、必ずやり遂げようと思った。これをやることによって人材は育成されるであろうと考えたが、見事に実証され、このプロジェクトに携わったエンジニアは苦しいが楽しそうで目を輝かせていた。富士通に入社した時に感じたエンジニアの生き生きとした姿を再現できた。そうしてやっていく内に多くの方々が応援してくれるようになった。
設計・開発時には、前例のない超超並列システムで動くはずがないと言うソフト屋とは大バトルがあった。ストロングコーヒー(眠っていたものを目覚めさせる)などと銘うって自由な議論の場を設け、アプリケーション開発者も巻き込んで一緒に使い道を考え、設計途中で必要なら変更をいとわないことで進めた。試作機では全く動かない部分が出てきたが、本格製造開始は迫っており、大英断をしなければならないこともあった。何としてもやり遂げようとする各人の想いが問題解決に繋がった。伝統から飛躍し、堅実にやるものもあったが、大冒険をしながらの設計・開発であった。
導入時には、筐体800台超、ケーブル20万本からなる巨大なシステムを一気に構築するため、緻密な作業の連続で、社内のみならず関連会社の協力が必要であった。慎重に慎重を期し、ケーブル接続や敷設の練習を行い、神戸の現場では床下配線の筐体への立ち上げの工夫を行い、やりながら改善していった。仲間意識で徹底的に現場力を高めた。そして、成し遂げる、納期を守るという強い意識を持って、設計から開発、製造、現場(工事・現調・保守)の総力を結集して、LINPACKベンチマークの世界一を達成できた。
7.これから
今年になって、友人の伊藤英紀氏(富士通研究所ITシステム研究所デザインイノベーション研究部)は自分の作った将棋ソフト「ボンクラーズ」で、周到な準備をして臨んだ米長永世棋聖を破った。名人と言われる人は素人には持てない大局観を持っている。このソフトは公開されているコンピュータ将棋ソフト「ボナンザ」をベースに並列処理化したものである。一手一手の評価はするものの、幾つかの手を試行し、さらに先の手を試行し、その中から有望な手を選び出し、先を見て全体像を浮かび上がらせる。次に打つ手が例え不利に見えても、先になって有利になる手を打つという、まさに名人の大局感を手に入れたソフトである。「ボンクラーズ」は洒落た名前で、ボンクラの集まりのコンピュータソフトが大局感を持って、永世棋聖を破るという快挙を成し遂げた。
スマートフォンに話し掛けると翻訳して他の言語で語り返してくれる。この処理はスマートフォンの中で行なっているのではなく、一部のソフトは動いているものの、極論すればスマートフォンには入力・表示・通信の機能があればよく、サービスは雲(クラウド)の向こうで誰かが行なっている。雲の向こうで処理して送り返してくる。
ビッグデータがサービス提供者に集まり、集まったデータを統計処理すると種々のことが分かり、サービスをすればするほど磨かれて、お金も儲かる時代が到来している。これがクラウドの真髄であって、恐ろしいものである。クラウドの向こうにあるコンピュータは実態が見えないが、新しいデータを次々と獲得し、そこから新しい知識を引き出し、デジタルデータとして記憶させれば永遠に残り、そのデータを広めていくことができる。その処理をするコンピュータはますます速くなる。そうして無限の叡智の世界がコンピュータによって築かれようとしている。最初にコンピュータは人間の作ったシミュレーションの道具だと言ったが、無限の叡智を持った道具になってきている。
この進化は他へも波及する。例えば、ソニーとパナソニックの提携のニュースがあったが、テレビは家庭内に置いた大きくて見易い画面を提供する道具であるものの、無限の叡智を作り出すコンピュータが背後にあることを踏まえてテレビは根源的に何をすべきかを考えない限り、一次凌ぎができてもビジネスとして成功しないだろう。
8.まとめ
「京」を作るに当って、非常に長い歴史の集大成ということもあり、環境も変わってきたが、巨大なものから沢山の集合体にするよう概念を替えたことは決して間違っていなかった。CPUもインターコネクトも独自技術を採用し、ソフトウェアも並列から超並列、超超並列へと進化させ、沢山の困難があったがやり遂げようとしている。
超超並列の世界になり、日本発の優れたソフトが無いと言われている中で、今がチャンスである。無限の叡智を生み出せる道具を手にしようとする今、誰にも成し遂げられない超超並列を使うソフトを書いた者が覇者になれると思う。ソフト屋さんに火を付けたかったことも「京」を作った隠れた動機である。したがって、ハードウェアはまだまだレガシーな造りでかなり大きいが、やがては掌に乗るようなものにすることを夢見つつ、ソフト屋さんに頑張ってもらい、無限の叡智を生み出す道具を日本の技術で我々の手にして、日本のみならず人類や地球のレベルでの危機に立ち向かうのに役立てて欲しいと思っている。これからは若い人達に挑戦して欲しいし、それを支えていくのが我々の仕事である。
9.Q&A
Q1: ケーブルが壊れた場合の迂回路は?
A1: 3次元トーラスでXYZの三軸に繋がっているが、それだけでは一つのノードの不具合で切れてしまう。三次元で繋がっていることを前提にソフトが書かれているので、切れているのは致命的である。三次元で繋がった一つの集合体には12個の密に繋がり合ったノードがあり、どこが壊れても、XYZに繋がるように考案した。壊れたケーブルがあっても、そのままにしておき、壊れたケーブルも迂回するようにする。
Q2: 性能を上げる場合は、チップから出る熱が問題でケーブルからの発生熱は問題ないか?
A2: ケーブル自体の発熱は問題ないが、ケーブルをドライブするところにシリアルデータを高速で送るSERDESという回路がある。この回路の動作を速くすると、チップの中の演算器の発熱を上回る可能性が出てくる。大きなシステムで、一つの単位をどの程度にし、両者の発熱のバランスをどうするか、選択が難しい。
一方、CPUの電力については、GPGPUを使う手はある。動画のゲームのように、画素数の多い画像を速く動かすためには、周波数が高くなくても、沢山の演算器を用意すればよく、消費電力は周波数の3乗に比例することから、消費電力を抑えることができる。このような画像処理用のエンジンを汎用的に使えるようにしたものがGPGPUであり、これをスーパーコンピュータに搭載すれば、演算速度だけは速くなるが、実際のアプリケーションでは効率が低く、スーパーコンピュータの汎用性が問われることになる。
Q3: 量子コンピュータが実用化されても、熱のバランスが重要になるか?
A3: 量子コンピューティング、生体素子、光コンピューティングなど新しい素子の研究は進めて欲しいが、未だ大量に均質なものができる工業製品になっていない。一方、大量生産に適した素子であるCMOSは今後もまだ集積度が上がるから簡単には置き換わらないだろう。それはさておき、量子コンピュータが今後実用化されても、おそらくはスーパーコンピュータのような並列化したマシンではノード(コンピュータ)間の伝送のためのエネルギーによって熱の問題が出てくるだろう。
Q4: 「京」に対する負け組となった米国や中国は、何を狙っていくか?
A4: 米国や中国は負け組どころか脅威だ。「京」をやっていく段階で特に脅威だったのは、米国IBMの「ブルーウオーター」であった。しかし、システムボードが巨大でそれを使って巨大システムを構築するには無理があったことと、お金が掛かり過ぎることから断念したのだろう。巨大で難しいものを大量生産するのは至難であり、我々は造りがレガシーであるので密度は低いが確実に作れる方を選んだ。もう一つ走っているIBMのマシンは、「セコイア」(Blue Gene/Q)である。1個1個が小粒でも超超並列にするアイディアの先鞭を付けたのはIBMのBlue Geneプロジェクトであったが、彼らは1個1個を強力にする方向での進化を選んだため冷却構造が複雑になった。昨年世界一に返り咲く予定であったが、この複雑さと開発遅れには関係があるだろう。米国はお金があり、オークリッジ研のプロジェクト「ジャガー」が伏兵と思っている。パソコンに載っているようなCPUと同じようなOpteronというCPUを使用して堅実に進めている。CPUは進歩するので、置き換えることにより「タイタン」として生まれ変わる。
スーパーコンピュータの性能は11年で1,000倍になるので、1~2年間で抜かれるのは止むを得ないが、世界一を奪還できる技術レベルを保つことが大事である。
A5: スパコンに対するサイバー攻撃は?
Q5: サイバー攻撃の対象にはなり難かった。富士通の場合は独自システムのため、富士通のマシ ンがないとウイルスも作れない。幸いに高価なマシンのため、比較的ガードが固い。ウイルスやスパイウェアは通常パソコンで作るので、パソコンと同じCPUを使ったスパコンが大きな地位を占めるようになってきたので、ガードが必要である。 (記録:池田)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||